关键节点组挖掘(附Python实现) |
您所在的位置:网站首页 › 网络 关键节点是指什么内容 › 关键节点组挖掘(附Python实现) |
关键节点组挖掘(附Python实现)
|
一、实验内容简介
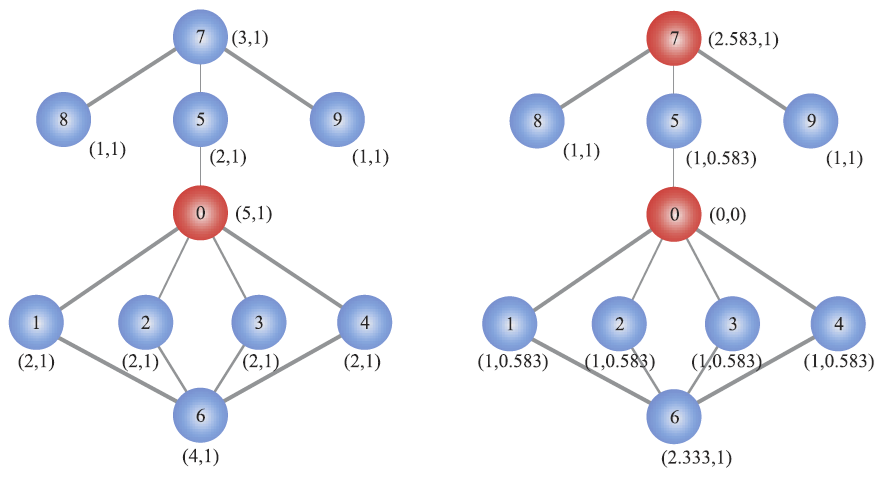
该实验主要利用基于度的排序和基于投票策略的排序分别挖掘出一组重要节点作为种子节点,然后在给定的网络中传播,一直到稳态,然后统计感染的规模NR。最后通过比较两种方法的感染规模给出相应的评价,给出不同感染率和不同种子节点条件下的实验结果。 二、算法说明首先是数据结构的选取,根据数据是稀疏图和有向图的特点,这里选择十字链表来存储。 然后是两种排序策略。第一种是基于度的排序,思想很简单,就是根据度的大小来对节点进行排序,选取前n个节点作为种子节点。第二种是基于投票策略的排序。比上一个要复杂一点,每一个节点有投票能力和投票分数。每次选出得票数最高的节点,当选出一个节点后,该节点的投票能力和投票分数变为0,其相邻节点的投票能力和投票分数会相应地下降。这样的话选取的节点就会相对分散,避免度数高的节点扎堆的情况。 为什么需要排序?因为每个节点的重要程度不一样。直觉是位于中心的节点比位于位于边缘的节点更重要,~~直接比就完事!~~我们当然不能仅凭直觉,需要相应的算法证明这一点。
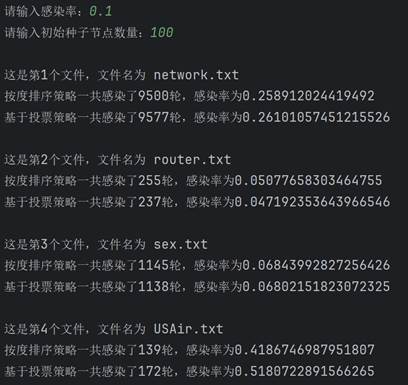
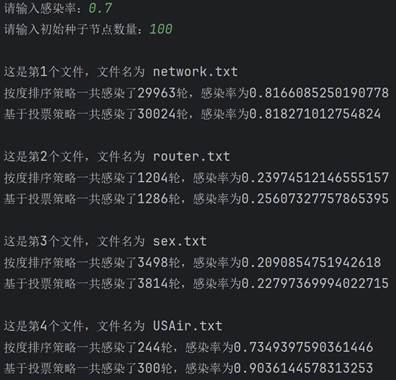
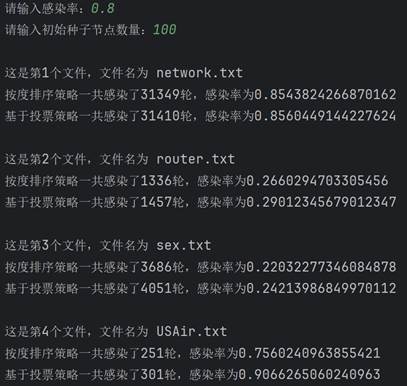
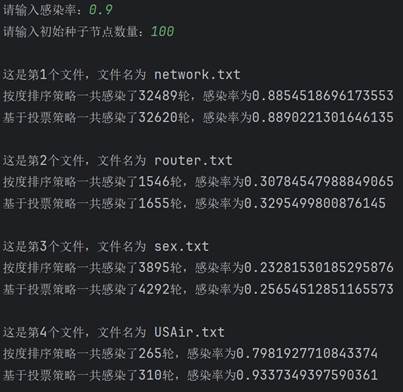
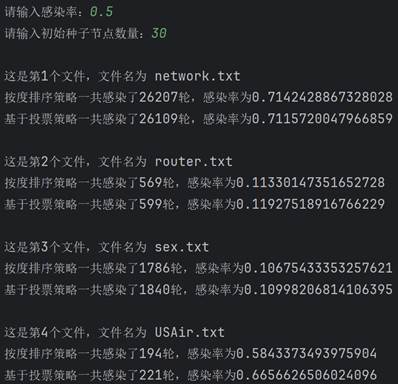
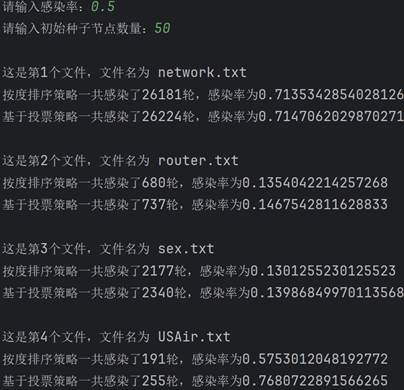
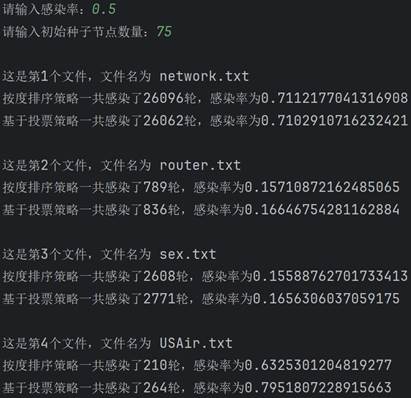
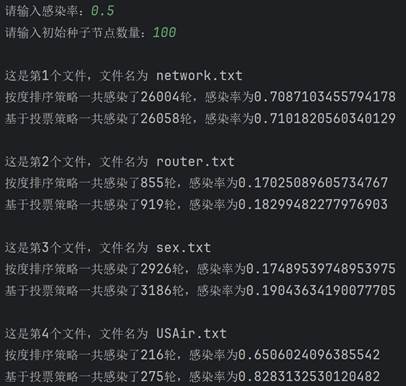
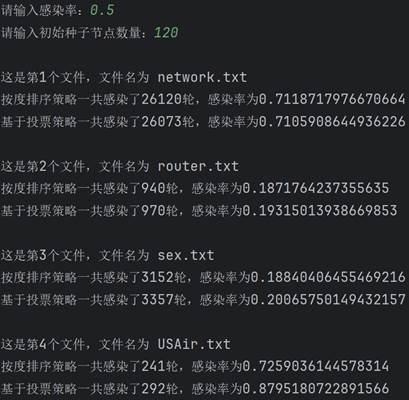
学习完算法的基本原理后,现在开始真正实现该算法。首先需要建图。要建图就要先找数据,我这里直接直接从网上找了现成的数据(bing搜索“重要节点组挖掘”的第一个搜索结果),有四个文件,正好拿来对比结果。每个数据第一行都是两个数字,点的数量和边的数量。读取后按点的数量建图,依次建立十字链表。 class Node: # 节点的关键代码 def __init__(self, value): self.value = value self.parents = [] self.children = []图建好后,就具体实现两种排序。按度排序很简单,值得一提的是,因为是有向图,又要代表传播能力,这里统一使用出度来代表度。Python代码很简单: temp=sorted(self.graph1,key=lambda l: l.chudu, reverse=True)[:self.num]接着实现基于投票策略的排序。其实投票策略有很多种,这里选取比较简单的一种,即投票能力按比例降低,降低比例为60%,并且是二阶降低。代码实现略微复杂一些: temp = [] for i in range(self.num): a = max(self.graph2, key=lambda l: l.score) temp.append(a) for j in a.children: for k in self.graph2[j].parents: self.graph2[k].score -= self.graph2[j].ability * 0.6 self.graph2[j].score -= a.ability self.graph2[j].ability *= 0.4 a.ability = 0 a.score = 0最后实现SIR模型。核心实现过程就是构建一个队列,先让种子节点进入这个队列。然后队列每出来一个节点,就遍历这个节点的子孙节点,以感染率作为概率把感染的节点加入队列。不断重复,直到队列为空。把康复者的数量作为总的数量来作为感染规模。下面是队列核心的操作: while sir_list[1]: for i in queue[0].children: if graph[i].sir == 0 and np.random.binomial(1, self.alpha, 1)[0]: graph[i].sir = 1 sir_list[0] -= 1 sir_list[1] += 1 queue.append(graph[i]) queue.pop(0) sir_list[1] -= 1 sir_list[2] += 1 lunshu += 1 四、测试结果在写完代码后,就可以开始测试了。主要的参数就是感染率和种子节点数量,感染率在0到1之间,种子节点数量在1到120之间。 在测试之前首先感谢数据来源:RankVote_重要节点组挖掘 - xxxl’s Blog (4ever-xxxl.github.io) 然后开始测试。首先固定种子节点数量在100不变,感染率依次从低到高,分别给出相应的结果。
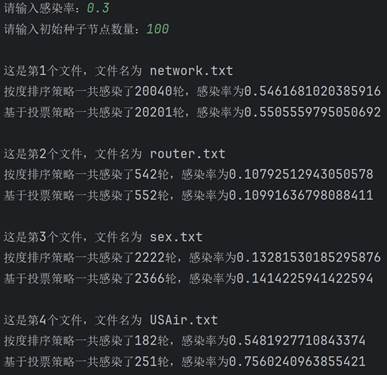
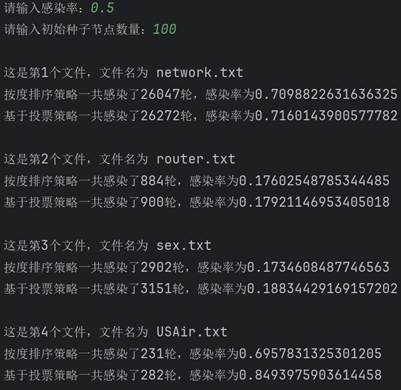
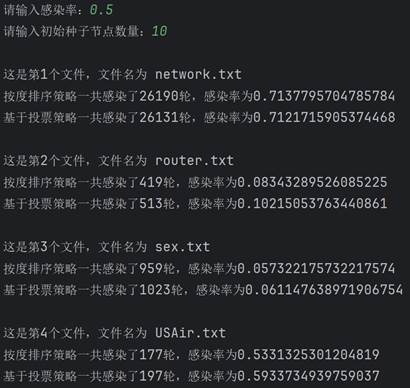
可以看到,两种策略的感染规模和感染轮数都随着感染率的上升而上升,并且在初始种子节点数量相同时,基于投票策略一般都要比按度排序策略的感染规模要大一些。 然后固定感染率0.5不变,改变种子节点数量再来测试。
可以看到,随着种子节点数量的增长,感染规模也在不断上升。同时也可以看到,在大多数情况下,基于投票策略一般比按度排序策略的感染规模大。这里有一个例外,就是第一个文件的图,两种策略的结果相差不大,具体原因下面开始分析。 五、分析与探讨测试完毕后,开始分析产生这种测试结果的原因。感染率不变,初始种子节点越多,感染规模越大;初始种子节点数量不变,感染率越大,感染规模越大。这是符合经验和常识的,应该不需要过多解释。接下来简单解释在感染率和初始种子节点相同的情况下,按度排序策略与基于投票策略最终的感染规模的差异。大体来说,基于投票策略最终的感染规模会更大一些,因为投票策略削弱了度数比较高的聚集在一起的节点群的优势,使节点更加分散,因此效果更好。但第一个文件中是个例外,大概原因是本来度数较高的节点在原来图的节点就比较分散,这时投票策略就没有太大的优势了。但因为这种是偶然的,是特殊情形。总的来说,基于投票的策略更优一些,效果更好一些。 最后,基于投票策略的算法还可以继续改进,不同的投票策略所导致的最后的感染规模差异也比较大。高效算法如机器学习里面的投票方法等,是以后改进的方向。另外,除了这两种方法以外,还有其他的选取种子节点的更高效方法,如通过计算该节点到其他各个节点的最短路径的长度之和的倒数作为排序依据等,值得未来学习和应用。 附录:源代码 """ 对给定的网络,采用十字链表建立网络 采用度选择策略和基于投票的策略选出一组重要节点的算法设计及实现 试验对比,分析不同初始种子节点数量情况下,两种方法的感染规模对比;不同感染率alpha情况下,两种方法的对比 """ import copy import re import numpy as np # 图的节点 class Node: def __init__(self, value): self.value = value self.parents = [] self.children = [] self.chudu = 0 self.score = 0 self.ability = 1 self.sir = 0 # 0表示易感者,1表示感染者,2表示恢复并免疫者 def __str__(self): return str(self.chudu) + ',' + str(self.ability) # 算法实现 class SIR: def __init__(self, graph, alpha, num): """传进来已经构建好的图""" self.graph = graph self.num = num self.graph1 = [copy.deepcopy(i) for i in graph] self.graph2 = [copy.deepcopy(i) for i in graph] self.graph1_sir = [len(graph) - num, num, 0] self.graph2_sir = [len(graph) - num, num, 0] self.alpha = alpha # 感染率 self.beta = 1 # 康复率 def sortByDegree(self): """按度(出度)排序""" temp = sorted(self.graph1, key=lambda l: l.chudu, reverse=True)[:self.num] for i in temp: i.sir = 1 def sortByVote(self): """基于投票策略的排序""" temp = [] for i in range(self.num): a = max(self.graph2, key=lambda l: l.score) temp.append(a) for j in a.children: for k in self.graph2[j].parents: self.graph2[k].score -= self.graph2[j].ability * 0.6 self.graph2[j].score -= a.ability self.graph2[j].ability *= 0.4 a.ability = 0 a.score = 0 for i in temp: i.sir = 1 def sir(self): """ 分别使用两种排序挖掘关键节点组,利用sir模型对比两种方法的差异 :return: """ self.sortByDegree() self.sortByVote() lunshu1, guimo1 = self.test(self.graph1, self.graph1_sir) lunshu2, guimo2 = self.test(self.graph2, self.graph2_sir) print(f"按度排序策略一共感染了{lunshu1}轮,感染率为{guimo1}") print(f"基于投票策略一共感染了{lunshu2}轮,感染率为{guimo2}") def test(self, graph, sir_list): """ 计算感染率和感染轮数 :param graph: 图 :param sir_list: sir参数 :return: 感染率和感染轮数 """ lunshu = 0 # 轮数 queue = [] for i in graph: if i.sir == 1: queue.append(i) while sir_list[1]: for i in queue[0].children: if graph[i].sir == 0 and np.random.binomial(1, self.alpha, 1)[0]: graph[i].sir = 1 sir_list[0] -= 1 sir_list[1] += 1 queue.append(graph[i]) queue.pop(0) sir_list[1] -= 1 sir_list[2] += 1 lunshu += 1 return lunshu, sir_list[2] / len(graph) if __name__ == '__main__': data = ['network.txt', 'router.txt', 'sex.txt', 'USAir.txt'] alpha = float(input('请输入感染率:')) num = int(input("请输入初始种子节点数量:")) if alpha > 1 or alpha |
【本文地址】
今日新闻 |
推荐新闻 |